[Spring Boot에서 캐시(Cache) 활용하기] - 캐시 개념과 기본 사용법

단순한 조회 작업마다 매번 데이터베이스를 호출하는 것은 비효율적일 수 있다. 서비스의 규모가 커지고 트래픽이 증가할수록 이러한 비효율은 더욱 두드러진다.
이럴 때 캐시는 문제를 해결할 수 있는 효과적인 방법 중 하나다. 자주 접근하는 데이터를 미리 저장해두고 필요할 때 빠르게 제공함으로써 데이터베이스 부하를 줄이고, 응답 시간을 단축시킬 수 있다.
이번 포스트에서는 캐시의 기본 개념부터 특징, 그리고 Spring Boot에서 캐시를 활용하는 방법까지 단계적으로 알아보자.
캐시(Cache)?
– 캐시는 데이터를 더 빠르게 접근할 수 있는 고속 저장소이다. 자주 사용되는 데이터나 반복적으로 조회되는 데이터를 케시에 저장하면 데이터베이스를 호출하지 않고도 빠르게 반환할 수 있다. 이를 통해 조회 속도를 높일 수 있을 뿐만 아니라, 데이터베이스의 부하가 크게 줄어들어 결과적으로 전체적인 서비스 성능을 향상시킬 수 있다.
캐시는 다양한 방식으로 구현된다. 대표적으로 로컬 캐시와 글로벌(분산)캐시로 구분할 수 있다.
글로벌 캐시(Global Cache)
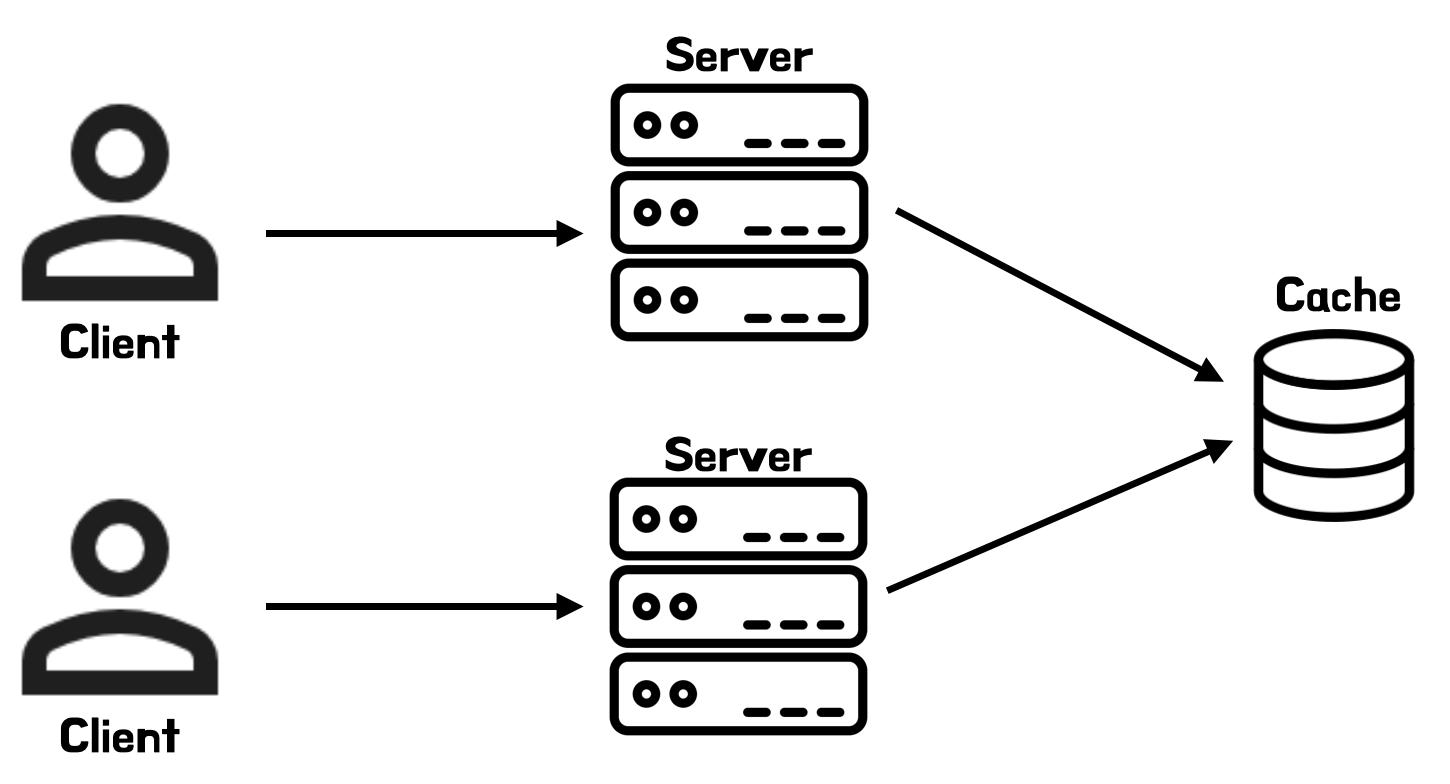 글로벌 캐시를 사용
글로벌 캐시를 사용- 별도의 캐시 서버에 데이터를 저장하고, 여러 애플리케이션 서버나 서비스에서 이를 공유하는 캐시 방식
- 각 애플리케이션 서버는 네트워크를 통해 중앙 캐시 서버에 접근
- 예시:
로컬 캐시(Local Cache)
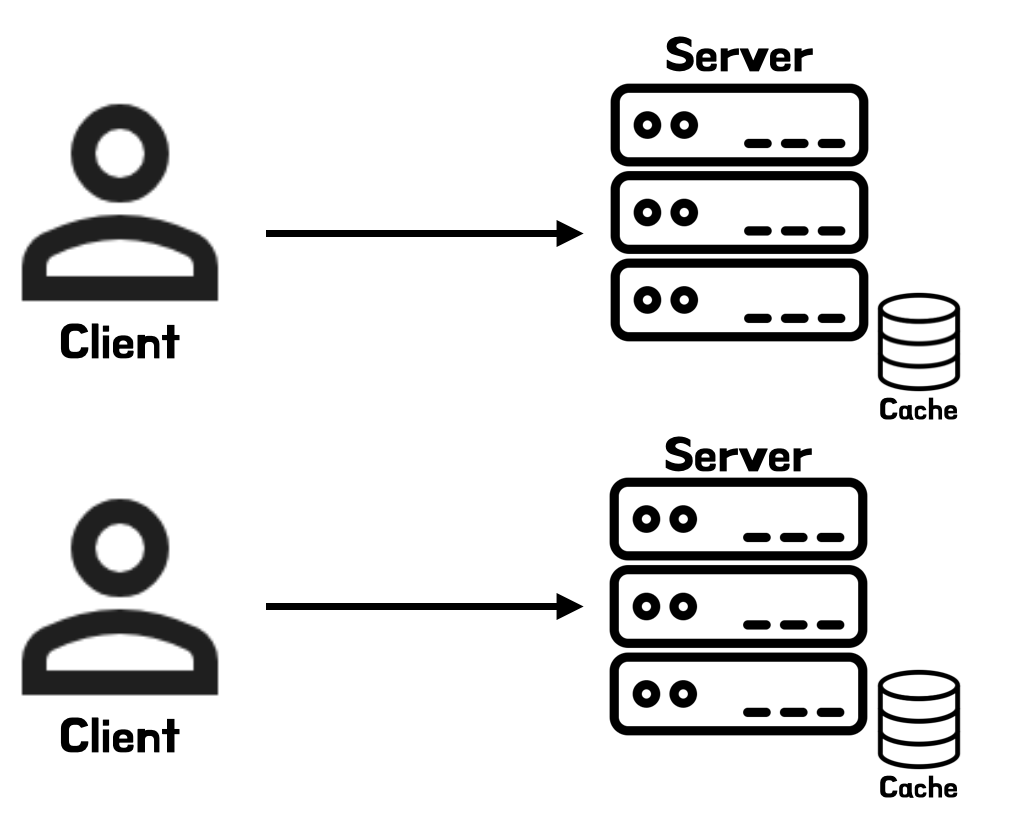 로컬 캐시를 사용
로컬 캐시를 사용- 각 애플리케이션 서버의 메모리 내부에 데이터를 저장하는 캐시 방식
- 각 서버는 자체적인 캐시를 유지하며 다른 서버와 공유하지 않음
가장 잘 알려진 글로벌 캐시로는 바로 레디스(Redis)가 있다. 레디스를 사용하게 될 경우 서버 간 데이터 공유가 가능하여 클라이언트는 모두 같은 데이터를 바라본다.
로컬캐시를 사용할 경우, 서버 간 데이터 공유가 불가능하기 때문에 캐싱된 데이터에 따라 서버 간 데이터 불일치 문제가 발생할 수 있다.
Spring에서 Caching
스프링에서는 캐시를 어떻게 지원하는지 알아보자.
캐시 추상화(Cache Abstraction)
스프링에서는 캐시 추상화를 제공하여 다양한 캐시 구현체를 일관된 방식으로 사용할 수 있게 해준다.
이 추상화는 캐싱 로직을 작성할 필요가 없게 해주지만 실제 데이터 저장소는 제공하지 않는다. 핵심적으로 추상화는 Java 메서드에 캐싱을 적용함으로써 캐시에 보관된 정보로 메서드의 실행 횟수를 줄여준다. 즉, 대상 메서드가 실행될 때마다 추상화가 해당 메서드의 결과를 캐시에 저장하고, 동일한 입력에 대해서는 메서드를 실행하지 않고 캐시된 결과를 반환한다
이 추상화는 다음 두 인터페이스로 구체화된다:
org.springframework.cache.Cache- 스프링 프레임워크의 캐시 추상화 계층에서 공통 캐시 연산을 정의하는 인터페이스
- 인터페이스는 다양한 캐시 구현체와 무관하게 일관된 방식으로 캐시를 사용할 수 있도록 해준다.
org.springframework.cache.CacheManager- 스프링 프레임워크에서 캐시 인스턴스를 중앙에서 관리하는 인터페이스로, 캐시 추상화의 핵심 구성 요소
캐시 추상화는 다중 스레드 및 다중 프로세스 환경에서 특별한 처리가 없으며, 이러한 기능은 캐시 구현에 의해 처리된다.
다중 프로세스 환경이 있는 경우, 애플리케이션 실행 중에 데이터를 변경하는 경우 다른 전파 메커니즘을 활성화해야 한다.
잠금이 적용되지 않으며, 여러 스레드가 동시에 동일한 항목을 로드하려고 할 수 있다. 퇴출(eviction)에도 동일하게 적용된다. 여러 스레드가 동시에 데이터를 업데이트하거나 제거하려고 하면, 오래된 데이터를 사용할 수 있다.
캐시 추상화를 사용하려면 두 가지 측면을 주의해야 한다
- 캐시 선언: 캐시가 필요한 메서드와 그 정책을 식별
- 캐시 구성: 데이터가 저장되고 읽히는 백업 캐시를 구성
캐시 추상화 적용 방법
스프링은 AOP 방식으로 메서드에 캐시를 적용할 수 있도록 다음과 같은 어노테이션을 제공한다.
1. 캐시 활성화하기
스프링 캐시 추상화를 사용하려면 먼저 애플리케이션에서 캐싱을 활성화해야 한다. 이는 @EnableCaching 어노테이션을 @Configuration 클래스에 추가하고, CacheManager 인터페이스를 구현하는 빈을 등록하면 된다.
2. 캐시 어노테이션 사용하기
@Transactional과 AOP를 통해 애플리케이션에 캐싱 동작이 추가되는 방식에 영향을 미치는 다양한 옵션을 지정할 수 있다.
@Cacheable- 캐시에 데이터가 없을 경우에는 기존의 로직을 실행한 후, 캐시에 데이터를 추가하고, 캐시에 데이터가 있으면 캐시에 저장된 데이터를 반환한다.
- 메서드에 전달한 인수가 같을 때는
@Cacheable이 붙은 메서드를 호출하지 않는다.
1 2 3 4 5
@Cacheable(cacheNames = "books", key = "#isbn") public Book findBook(String isbn) { // 이 메서드는 동일한 isbn으로 호출될 때 캐시된 결과를 반환 return bookRepository.findByIsbn(isbn); }
@CacheEvict- 캐시에서 데이터를 제거할 때 사용한다.
allEntries속성을true로 설정하면 캐시의 모든 항목을 제거할 수 있다.
1 2 3 4 5
@CacheEvict(cacheNames = "books", key = "#isbn") public void removeBook(String isbn) { // 이 메서드가 실행되면 books 캐시에서 해당 isbn의 항목이 제거됨 bookRepository.deleteByIsbn(isbn); }
@CachePut- 메서드 실행 결과를 저장하지만, 메서드 실행 자체는 캐시 여부와 상관없이 항상 실행된다.
- 데이터를 갱신할 때 사용한다.
1 2 3 4 5
@CachePut(cacheNames = "books", key = "#book.isbn") public Book updateBook(Book book) { // 이 메서드는 항상 실행되고, 결과가 캐시에 저장됨 return bookRepository.save(book); }
@Caching- 여러 캐시 작업을 하나의 메서드로 구룹화
1 2 3 4 5 6 7 8 9 10 11
@Caching( evict = { @CacheEvict("books"), @CacheEvict(value = "authors", key = "#book.authorId") }, put = { @CachePut(value = "books", key = "#book.isbn") } ) public Book updateBookAndAuthor(Book book) { // 복잡한 캐싱 로직 return bookService.updateBookAndAuthor(book); }
3. 캐시 키 생성
캐시는 근본적으로 key-value 구조를 가진 저장소이다. 캐시가 적용된 메서드들은 각각 캐시에 접근하기 위한 적절한 키를 생성하게 된다. 기본적으로 캐싱 추상화는 SimpleKeyGenerator를 사용한다.
- 파라미터가 없는 경우: 기본값인 0을 키로 사용
- 파라미터가 하나인 경우: 해당 파라미터를 키로 사용
- 파라미터가 여러 개인 경우: 모든 파라미터의 hashCode()를 조합하여 키로 사용
4. 조건부 캐싱
모든 상황에서 캐싱이 적합하지 않을 수 있다. 이 때 스프링은 SpEL을 사용하여 조건에 따라 캐시를 적용할 수 있도록 해준다.
1
2
3
4
5
@Cacheable(cacheNames = "books", condition = "#isbn.length() < 13")
public Book findBook(String isbn) {
// isbn 길이가 13 미만인 경우에만 캐싱 적용
return bookRepository.findByIsbn(isbn);
}
프로그래밍 방식으로 캐시 사용
선언적 캐시 어노테이션 외에도, 스프링의 캐시 추상화는 프로그래밍 방식(명령형)으로 캐시를 직접 제어할 수 있는 API를 제공한다. 이 방식은 동적으로 캐시를 제어해야 하거나, 어노테이션 기반 접근이 어려운 상황에서 유용하다.
일반적으로 CacheManager를 주입받아 원하는 캐시 인스턴스를 가져오고, 그 위에서 데이터를 조회하거나 저장, 삭제할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
@Service
public class BookCacheService {
@Autowired
private CacheManager cacheManager;
// 캐시에서 isbn에 해당하는 Book 객체를 조회
public Book getBookFromCache(String isbn) {
// "books"라는 이름의 캐시 인스턴스 획득
Cache cache = cacheManager.getCache("books");
if (cache != null) {
// 캐시에 값이 있으면 반환, 없으면 null
return cache.get(isbn, Book.class);
}
return null;
}
// 캐시에 Book 객체 저장
public void putBookToCache(String isbn, Book book) {
// "books"라는 이름의 캐시 인스턴스 획득
Cache cache = cacheManager.getCache("books");
if (cache != null) {
// 캐시에 (isbn, book) 쌍으로 저장
cache.put(isbn, book);
}
}
// 캐시에서 특정 isbn에 해당하는 데이터를 제거
public void evictBookFromCache(String isbn) {
// "books"라는 이름의 캐시 인스턴스 획득
Cache cache = cacheManager.getCache("books");
if (cache != null) {
// 해당 isbn 키에 대한 캐시 데이터 제거
cache.evict(isbn);
}
}
}
마무리
이번 포스트에서는 캐시의 기본 개념과 Spring에서 제공하는 캐시 추상화에 대해 알아보았다. 캐시는 자주 접근하는 데이터를 빠르게 제공함으로써 데이터베이스 부하를 줄이고 응답 시간을 단축시키는 중요한 성능 최적화 도구이다.
하지만 캐시는 만능이 아니다. 데이터 일관성, 캐시 만료 정책, 캐시 크기 관리, 분산 환경에서의 동기화 등 반드시 고려해야 할 부분도 많다. 잘못된 캐시 전략은 오히려 시스템의 복잡도를 높이고, 예기치 않은 문제를 야기할 수 있다.
다음 포스트에서는 실제 애플리케이션에 로컬 캐시와 글로벌 캐시를 구현하는 방법에 대해 직접 코드로 살펴보고자 한다.